pythonでConfluenceをスクレイピング#3
実はConfluenceのAPIを使う部分は#2で終わってました。Confluenceから取得したデータをどのように解析するかについて実践していきたいと思います。

取得したデータの内容を確認する
前回までのコードでどのようなデータが取得できているのかデバッガを使ってデータの内容を確認します。
改めて現状のコードを載せておきます。
from atlassian import Confluence
if __name__ == '__main__':
confluence = Confluence(
url='https://<site-name>.atlassian.net/wiki/',
username='<mail address>',
password='<API token>')
page = confluence.get_page_by_id('<pageId>', expand='body.storage')
print(page)10行目にブレークポイントを貼ってデバッグを実行します。
ブレークするときにデバッグパースペクティブに切り替えるか確認されるので「常にこの設定を使用する」にチェックを入れておきます。
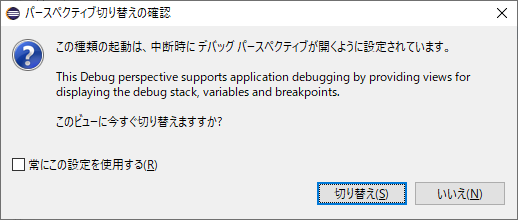
変数ビューで、「page>body>storage>value」を見ると、集計したい出勤計画のデータがhtml形式で入っていることがわかりました。valueに辿り着くまでのキーと各値の型がdictになっていることが確認できました。valueの値を取得する際は、page['body’]['storage’]['value’]ということになります。
では、ここで実行終了して次に進みます。
HTMLを構文解析する
目的のデータがHTML形式であることがわかったので、HTML構文解析のライブラリを使用します。今回はBeautifulSoup4(https://pypi.org/project/beautifulsoup4/)を使います。
BeatifulSoup4をインストールする
「ウィンドウ>設定」から「PyDev>インタープリター>Pythonインタープリター」を開き、「Manage with pip」をクリックします。
Manage pip画面で「Command to execute」に「install beautifulsoup4」を入力し実行します。
パッケージにbeautifulsoup4が追加されたことを確認し、「適用して閉じる」を押します。
BeautifulSoup4を使う
BeautifulSoupコンストラクタにHTMLデータ(page['body’]['storage’]['value’])を渡します。htmlの構文解析をするので、’html.parser’を指定します。
from atlassian import Confluence
from bs4 import BeautifulSoup
if __name__ == '__main__':
confluence = Confluence(
url='https://<site-name>.atlassian.net/wiki/',
username='<mail address>',
password='<API token>')
page = confluence.get_page_by_id('<pageId>', expand='body.storage')
soup = BeautifulSoup(page['body']['storage']['value'], 'html.parser')
print(soup)12行目にブレークポイントを設定してデバッグ起動してsoupの中身を確認します。
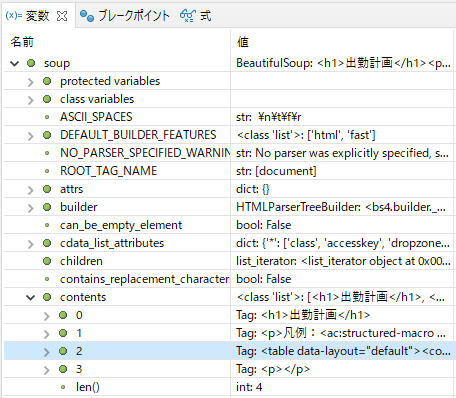
「soup>contents>2」に出勤計画表のデータがあることがわかるので、ここからデータを取り出せそうです。式ビューに「soup.findAll('table’)」と入力してみます。
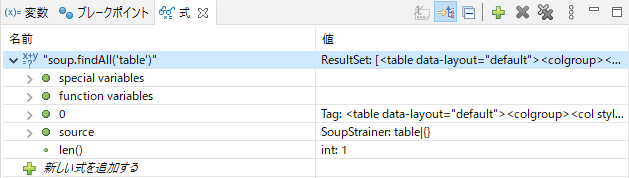
ResultSetの0に目的のデータが入っています。更に中身を確認してテーブルの各データがどのように入っているか確認しておきます。
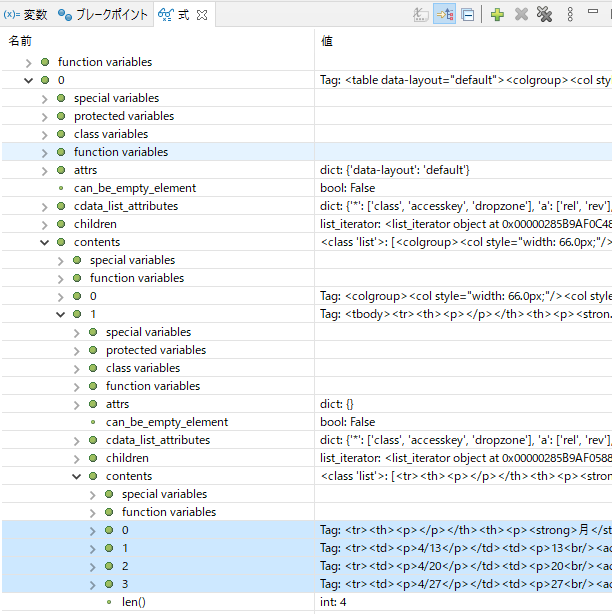
ここまで確認した内容でテーブルを操作するコードを追加してみます。
from atlassian import Confluence
from bs4 import BeautifulSoup
if __name__ == '__main__':
confluence = Confluence(
url='https://<site-name>.atlassian.net/wiki/',
username='<mail address>',
password='<API token>')
page = confluence.get_page_by_id('<pageId>', expand='body.storage')
soup = BeautifulSoup(page['body']['storage']['value'], 'html.parser')
table = soup.findAll('table')[0]
rows = table.findAll('tr')
for row in rows:
for cell in row.findAll('td'):
print(cell)これを実行してみます。
改めて出勤計画表の仕様を見てやりたいことを整理します。
- ヘッダに曜日が日本語で記載される
- 曜日は月曜日から始まる
- 左端の列のセルには月曜日の日付が記載される
- 左から2列目以降のセルは日付を表す
- 日付のセルには1行目に日付の数値が入り、2行目以降はメンバの出勤状況がステータス(色)で表現される
- 日付のセルの背景色が付いているセルは休みを表す
やりたいことを整理した結果は、
- セルの背景色が付いていないセルを計算対象にする
- 週毎に稼働日全体の出社率(出勤の数/メンバのステータス数)を計算する
- 週毎の出社率を表示する
さらにコードを書いていきます。
from atlassian import Confluence
from bs4 import BeautifulSoup
if __name__ == '__main__':
confluence = Confluence(
url='https://<site-name>.atlassian.net/wiki/',
username='<mail address>',
password='<API token>')
page = confluence.get_page_by_id('<pageId>', expand='body.storage')
soup = BeautifulSoup(page['body']['storage']['value'], 'html.parser')
table = soup.findAll('table')[0]
rows = table.findAll('tr')
for row in rows:
_cnt_attendance = 0
_cnt_all = 0
_week = ''
for cell in row.findAll('td'):
if cell.attrs.get('data-highlight-colour'):
continue
if cell.find('ac:parameter') == None:
week = cell.text
else:
colours = cell.findAll('ac:parameter', {'ac:name':'colour'})
_cnt_attendance += len([col for col in colours if col.text == 'Red'])
_cnt_all += len(colours)
if week != '':
print(','.join([week, f'{_cnt_attendance/_cnt_all:.2%}']))属性やタグの名前は随時デバッガで確認しながら書いていくとよいと思います。IDEがあると確認しながらのコーディングはとてもやりやすいです。それでは実行してみましょう。

うまく動いてそうです。かちょーの要求としてはこれで満たせたのでもっときれいにコードが書けるかもしれませんが、やりたいことがやれているので完了とします。

かちょー。
出社率の計算できました。

(30分以上経ってるけど…)
うちの課はいつでも集計出せるようになったね。ありがとう。